这几天在熟悉学习hbase,记录一下配置过程,以及出现的问题。
首先,hbase是什么?先来一段摘抄:
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
反正这款数据库在大数据领域是比较出名的,nosql、面向列,都是它的特点。
在安装之前,我们首先最好查看一下hbase和hadoop对应的版本是否兼容。官方文档地址:http://hbase.apache.org/book.html
看到“4. Basic Prerequisites”,往下拉到hadoop那里,有一个表格,表明了hadoop和hbase的兼容情况:
| HBase-0.94.x | HBase-0.98.x (Support for Hadoop 1.1+ is deprecated.) | HBase-1.0.x (Hadoop 1.x is NOT supported) | HBase-1.1.x | HBase-1.2.x | |
|---|---|---|---|---|---|
|
Hadoop-1.0.x |
X |
X |
X |
X |
X |
|
Hadoop-1.1.x |
S |
NT |
X |
X |
X |
|
Hadoop-0.23.x |
S |
X |
X |
X |
X |
|
Hadoop-2.0.x-alpha |
NT |
X |
X |
X |
X |
|
Hadoop-2.1.0-beta |
NT |
X |
X |
X |
X |
|
Hadoop-2.2.0 |
NT |
S |
NT |
NT |
NT |
|
Hadoop-2.3.x |
NT |
S |
NT |
NT |
NT |
|
Hadoop-2.4.x |
NT |
S |
S |
S |
S |
|
Hadoop-2.5.x |
NT |
S |
S |
S |
S |
|
Hadoop-2.6.0 |
X |
X |
X |
X |
X |
|
Hadoop-2.6.1+ |
NT |
NT |
NT |
NT |
S |
|
Hadoop-2.7.0 |
X |
X |
X |
X |
X |
|
Hadoop-2.7.1+ |
NT |
NT |
NT |
NT |
S |
我下载的是hbase-0.98.16.1-hadoop2-bin.tar.gz。
下面讲一下配置:
分布式配置
解压文件:
tar -zxvf hbase-0.98.16.1-hadoop2-bin.tar.gz -C /env/
切换到 hbase目录下的conf目录,编辑hbase-env.sh
vim hbase-env.sh
修改以下两行,并把原有的#去掉,第一行换上你jdk的目录,第二行表示使用hbase自带的zookeeper。
export JAVA_HOME=/usr/java/jdk1.7.0_79/ export HBASE_MANAGES_ZK=true
再修改hbase-site.xml
vim hbase-site.xml
改为以下内容,其中的主机名不要搞错,要在/etc/hosts里面有相应的映射。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://main:49002/hbase</value>
<description>The directory shared byRegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>main,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>
修改regionservers,我把slave1和slave2加进去
vim regionservers
内容修改为
slave1
slave2
一个节点占一行,保存。
把配置好的hbase复制到另外两台主机上
scp -r /env/hbase-0.98.16.1-hadoop2/ root@slave1:/env/ scp -r /env/hbase-0.98.16.1-hadoop2/ root@slave2:/env/
先启动hadoop的hdfs,然后再启动hbase即可。
在bin目录下,输入以下命令
./start-hbase.sh
不过,我是在虚拟机上弄的分布式环境,在运行hbase的shell的时候,HMaster老是自动退出,查看日志,看到是zookeeper的错误,错误如下:
zookeeper.ClientCnxn: Opening socket connection to server main/192.168.254.100:2299. Will not attempt to authenticate using SASL (unknown error)
2016-01-11 05:23:12,267 WARN [main-SendThread(main:2299)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
有点郁闷,找了好多解决方法,都不行,后来转念一想,既然是想熟悉一下hbase,运行一下它的shell,就不搞那么复杂了,重新配个单机版,单机版的配置非常简单。
单机版配置
和分布式配置的步骤基本一致,只需要把hbase-site.xml改为简易版的就行,内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>/home/hbase</value>
<description>The directory shared byRegionServers.
</description>
</property>
</configuration>
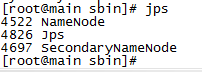
改为单机版之后,首先还是得运行hadoop的hdfs,然后再运行./start-hbase.sh,此时jps一下,看到hadoop的namenode启动了,hbase的Hmaster也启动了,此时再运行./hbase shell就正常了。下一篇转一篇文章,学习一下如何直接在shell操作数据库。
啊啊啊赶在12点断网之前。