这是RNN教程的第三部分。
RNN翻译教程目录:
在上一部分,我们从零开始实现了一个RNN,但是并没有对其中的BPTT算法作详细的解释。在这一部分,我们将简要的介绍一下RNN,并解释一下它和传统的反向传播算法有什么不同。接着,我们将会尝试着去理解梯度消失问题,也正是因为存在这个问题,LSTM和GRU才会被提出来,这两个模型在NLP领域相当流行。
为了深刻理解这部分教程,我建议你最好熟悉一下反向传播算法,下面三篇教程可供参考,他们的难度是逐渐增大的:
http://cs231n.github.io/optimization-2/
http://colah.github.io/posts/2015-08-Backprop/
http://neuralnetworksanddeeplearning.com/chap2.html
BPTT算法
让我们快速的回顾一下RNN的基本式子。注意,这里有个小小的改动,那就是 变成了
变成了 ,这是为了和要引用的一些文献保持一致:
,这是为了和要引用的一些文献保持一致:
![\[ s_{t}=\tanh(Ux_{t}+Ws_{t-1}) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-cd017e75dc25c7da4ef8332142d2486d_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{y}_{t}=\rm softmax(Vs_{t}) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-a78c973c8e204ea382704a04ad2914a0_l3.png "Rendered by QuickLaTeX.com")
同样,定义损失函数为交叉熵损失函数如下:

 是正确的标签,
是正确的标签, 是我们的预测。我们以一个句子序列为一个训练样本,所以总的误差就是每一个时间步(单词)的误差和。
是我们的预测。我们以一个句子序列为一个训练样本,所以总的误差就是每一个时间步(单词)的误差和。
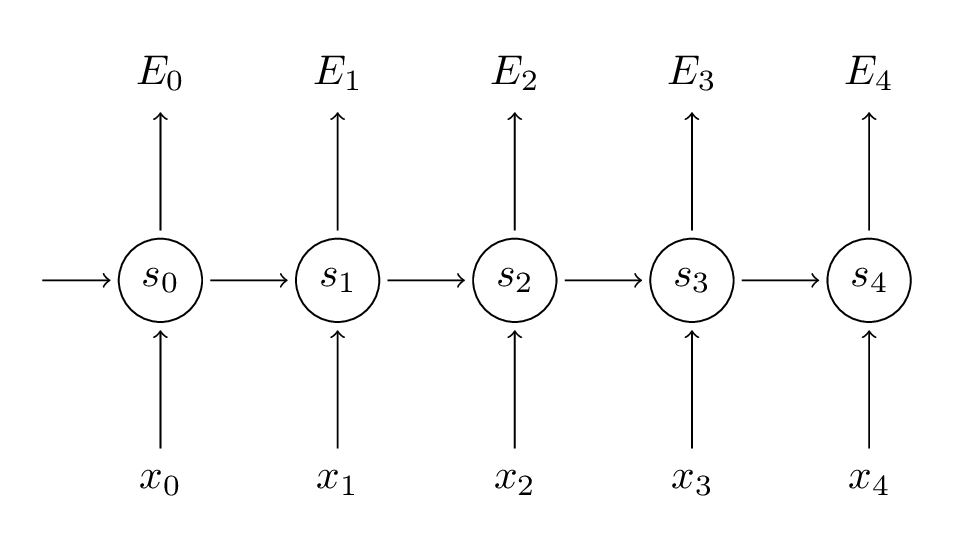
记住,我们的目标是计算误差对应U,V,W的梯度,从而用SGD算法来更新U,V,W。正如我们上面做的—把误差相加,在这里我们也把训练样本中每一个时间步的梯度相加起来:
![\[ \frac{\partial E}{\partial W}=\sum_{t} \frac{\partial E_{t}}{\partial W} \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-6a9cb39d56edb14d307addf2647e38e1_l3.png "Rendered by QuickLaTeX.com")
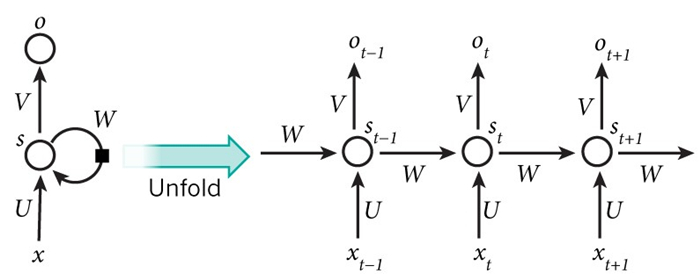
为了计算这些梯度,我们使用导数的链式法则。这正是反向传播算法中从最后一层将误差向前传播的思想。接下来,为了能有具体的理解,我们将用E3作为例子:
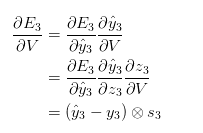
在上面的式子中, ,
, 是外积的意思。事实上,上面这个式子的推导还是省略了几个步骤的,包括softmax函数与交叉熵结合的求导,关于里面的细节,可以参考这两篇文章:
是外积的意思。事实上,上面这个式子的推导还是省略了几个步骤的,包括softmax函数与交叉熵结合的求导,关于里面的细节,可以参考这两篇文章:
http://www.jianshu.com/p/ffa51250ba2e
http://blog.csdn.net/u014313009/article/details/51045303
但这里的重点还不在于推导的过程,重点在于 这个值,只取决于当前时间步的一些值:
这个值,只取决于当前时间步的一些值: 、
、 、
、 ,如果你有了这些值,计算关于V的梯度只是简单的矩阵乘法而已。
,如果你有了这些值,计算关于V的梯度只是简单的矩阵乘法而已。
而对于 (还有U)而言,事情就不一样了,我们来看一下链式式子:
(还有U)而言,事情就不一样了,我们来看一下链式式子:

请注意, 这个式子取决于 的值,而由取决于
的值,而由取决于 和
和 的值…依此类推。所以,如果我们想得到相对于W的导数,我们就不能把当作一个常量。重新应用链式法则,我们得到:
的值…依此类推。所以,如果我们想得到相对于W的导数,我们就不能把当作一个常量。重新应用链式法则,我们得到:
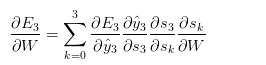
上面的式子用到了复合函数的链式求导法则。再上个图加深理解:
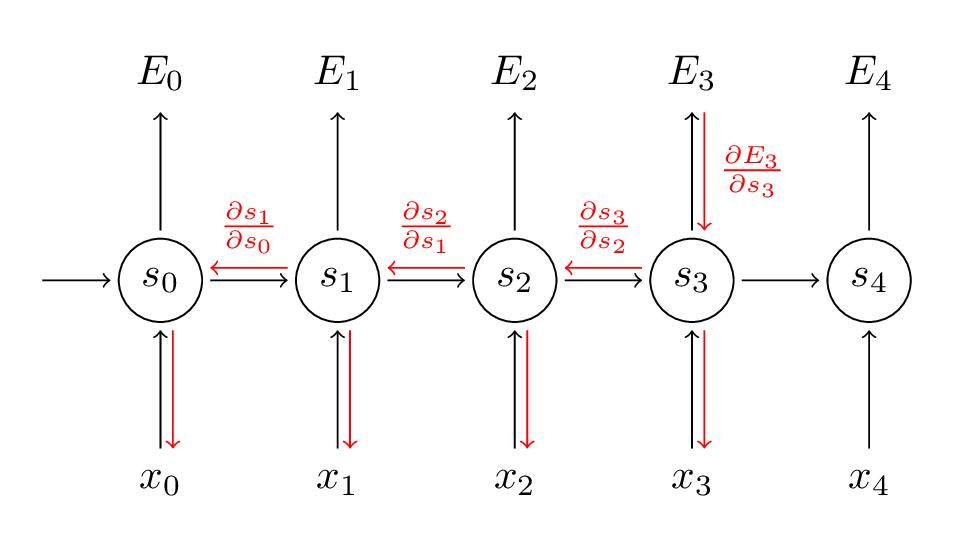
注意,上面的步骤其实和标准的反向传播算法是一样的,关键的不同在于我们将每个时间步对于W的梯度都加了起来。在传统的NN里面,我们不共享权重,所以我们不用做这种加法。和传统的反向传播算法一样,我们仍然可以定义残差,然后计算梯度。
下面上代码:
def bptt(self, x, y):
T = len(y)
# Perform forward propagation
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation: dL/dz
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]
从代码中我们可以看到,为什么RNN这么难以训练—因为序列太长了,可能超过20个单词,所以你要传播很多层。而在实际上,很多人将反向传播截断成比较少的步骤,正如上面代码中的bptt_truncate参数定义的那样。
梯度消失和梯度爆炸
关于这部分内容,就不翻译了,感兴趣的朋友可以参考我之前写过的【关于梯度消失和梯度爆炸】,而在原始RNN当中,这个问题尤其突出。
下一篇,也是最后一篇教程,我们将关注LSTM模型和GRU模型。
请问为何E3在对W求偏导时,不是如下:
αE3/αW = (αE3/αy^3) * (αy^3 /αs3) * (αs3/ αW)
= (y^3 – y3)(1-(s3)^2)s2
在前向传播完一次后,s3和s2是已知的,那么按照上式就已经可以求出αE3/αW,我的理解是这样,不知是否正确,希望得到您的回复,谢谢。
另,αE3/αV中有涉及到外积,是因为求导得到的是梯度是一个矢量,所以才是外积吗?
此外,为何不是:
αE3/αW = (αE3/αy^3) * (αy^3 /αs3) * (αs3/ αs2)
* (αs2/ αs1)* (αs1/ αW)
而是
αE3/αW = (αE3/αy^3) * (αy^3 /αs3) * (αs3/ αs0)
* (αs0/ αW)
+(αE3/αy^3) * (αy^3 /αs3) * (αs3/ αs1) * (αs1/ αW)
+(αE3/αy^3) * (αy^3 /αs3) * (αs3/ αs2)* (αs2/ αW)
s0其实是和W已经无关了?
不错学习了!