做项目要用到提取网页的正文内容,于是在网上找找有什么好用的库。先测试一下,发现python就有现成的库,叫做goose-extractor。
事不宜迟,开始安装吧。
pip install goose-extractor
什么?出现问题了。
在安装依赖的lxml的时候,出现了以下的错误提示:
Microsoft\\Visual C++ for Python\\9.0\\VC\\Bin\\amd64\\cl.exe’ failedwith exitstatus 2
找不到好的解决方案,最后祭出大杀器。直接用编译好的。
先打开http://www.lfd.uci.edu/~gohlke/pythonlibs/
ctrl+F搜索lxml,然后下载它对应的whl文件,下载之后pip install xxx.whl即可安装!
安装完这个比较难缠的lxml之后,就方便了,重新pip install goose-extractor
等待安装成功。
使用非常简单,给出一个实例代码,抓取《https://www.lookfor404.com/简易python爬虫–爬取冷笑话/》的正文内容。
# -*- coding: utf-8 -*-
from goose import Goose
from goose.text import StopWordsChinese
url = 'https://www.lookfor404.com/%e7%ae%80%e6%98%93python%e7%88%ac%e8%99%ab-%e7%88%ac%e5%8f%96%e5%86%b7%e7%ac%91%e8%af%9d/'
g = Goose({'stopwords_class': StopWordsChinese})
article = g.extract(url=url)
print article.cleaned_text
效果不错,截取一下控制台的输出:
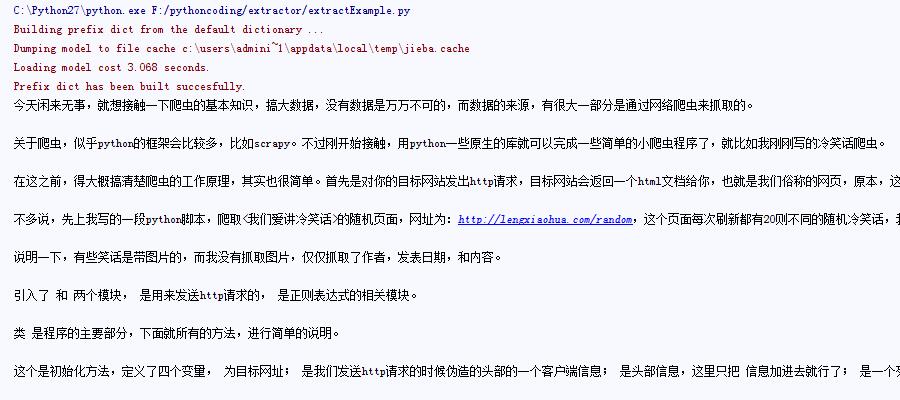
但是速度并不快,具体里面怎么实现的还没看,但是它要用到python的结巴分词,估计这个耗时久一点,另外还有一个问题,就是我<code>标签里面的内容,被过滤掉了,所以抓取技术文章,有点不合适,哈哈。